Les structures de données permettent de stocker des séries d’information et d’y accéder (plus ou moins) facilement et rapidement.
Les listes
Une collection d’éléments ordonnés référencé par un indice
animaux_favoris = [ "girafe", "chenille", "lynx" ]
fibonnaci = [ 1, 1, 2, 3, 5, 8 ]
stuff = [ 3.14, 42, "bidule", ["a", "b", "c"] ]
Accès à element particulier ou a une “tranche”
animaux_favoris[1] -> "chenille"
animaux_favoris[-2:] -> ["chenille", "lynx"]
Longueur
len(animaux_favoris) -> 3
Tester qu’un élément est (ou n’est pas) dans une liste
"lynx" in animaux_favoris # -> True
"Mewtwo" not in animaux_favoris # -> True
animaux_favoris = [ "girafe", "chenille", "lynx" ]
Iteration
for animal in animaux_favoris:
print(animal + " est un de mes animaux préférés !")
Iteration avec index
print("Voici la liste de mes animaux préférés:")
for i, animal in enumerate(animaux_favoris):
print(str(i+1) + " : " + animal)
animaux_favoris = [ "girafe", "chenille", "lynx" ]
Modification d’un élément
animaux_favoris[1] = "papillon"
Ajout à la suite, contatenation
animaux_favoris.append("coyote")
Insertion, concatenation
animaux_favoris.insert(1, "sanglier")
animaux_favoris += ["lion", "moineau"]
Exemple de manip classique : filtrer une liste pour en construire une nouvelle
animaux_favoris = [ "girafe", "chenille", "lynx" ]
# Création d'une liste vide
animaux_starting_with_c = []
# J'itère sur la liste de pokémons favoris
for animal in animaux_favoris:
# Si le nom de l'animal actuel commence par c
if animal.startswith("c"):
# Je l'ajoute à la liste
animaux_starting_with_B.append(animal)
À la fin, animaux_starting_with_c contient:
"Hello World".split() -> ["Hello", "World"]
' | '.join(["a", "b", "c"]) -> "a | b | c"
Les dictionnaires
Une collection non-ordonnée (apriori) de clefs a qui sont associées des valeurs
phone_numbers = { "Alice": "06 93 28 14 03",
"Bob": "06 84 19 37 47",
"Charlie": "04 92 84 92 03" }
Accès à une valeur
phone_numbers["Charlie"] -> "04 92 84 92 03"
phone_numbers["Marius"] -> KeyError !
phone_numbers.get("Marius", None) -> None
Modification d’une entrée, ajout d’une nouvelle entrée
phone_numbers["Charlie"] = "06 25 65 92 83"
phone_numbers["Deborah"] = "07 02 93 84 21"
Tester qu’une clef est dans le dictionnaire
"Marius" in phone_numbers # -> False
"Bob" not in phone_numbers # -> False
phone_numbers = { "Alice": "06 93 28 14 03",
"Bob": "06 84 19 37 47",
"Charlie": "04 92 84 92 03" }
Iteration sur les clefs
for prenom in phone_numbers: # Ou plus explicitement: phone_numbers.keys()
print("Je connais le numéro de "+prenom)
Iteration sur les valeurs
for phone_number in phone_numbers.values():
print("Quelqu'un a comme numéro " + phone_number)
Iterations sur les clefs et valeurs
for prenom, phone_number in phone_numbers.items():
print("Le numéro de " + prenom + " est " + phone_number)
Construction plus complexes
Liste de liste, liste de dict, dict de liste, dict de liste, …
contacts = { "Alice": { "phone": "06 93 28 14 03",
"email": "alice@megacorp.eu" },
"Bob": { "phone": "06 84 19 37 47",
"email": "bob.peterson@havard.edu.uk" },
"Charlie": { "phone": "04 92 84 92 03" } }
contacts = { "Alice": { "phone": "06 93 28 14 03",
"email": "alice@megacorp.eu" },
"Bob": { "phone": "06 84 19 37 47",
"email": "bob.peterson@harvard.edu.uk" },
"Charlie": { "phone": "04 92 84 92 03" } }
Recuperer le numero de Bob
contacts["Bob"]["phone"] # -> "06 84 19 37 47"
Ajouter l’email de Charlie
contacts["Charlie"]["email"] = "charlie@orange.fr"
Ajouter Deborah avec juste une adresse mail
contacts["Deborah"] = {"email": "deb@hotmail.fr"}
Les sets
Les sets sont des collections d’éléments unique et non-ordonnée
chat = set(["c", "h", "a", "t"]) # -> {'h', 'c', 'a', 't'}
chien = set(["c", "h", "i", "e", "n") # -> {'c', 'e', 'i', 'n', 'h'}
chat - chien # -> {'a', 't'}
chien - chat # -> {'i', 'n', 'e'}
chat & chien # -> {'h', 'c'}
chat | chien # -> {'c', 't', 'e', 'a', 'i', 'n', 'h'}
chat.add("z") # ajoute `z` à `chat`
Les tuples
Les tuples permettent de stocker des données de manière similaire à une liste, mais de manière non-mutable.
Generalement itérer sur un tuple n’a pas vraiment de sens…
Les tuples permettent de grouper des informations ensembles.
Typiquement : des coordonnées de point.
xyz = (2,3,5)
xyz[0] # -> 2
xyz[1] # -> 3
xyz[0] = 5 # -> Erreur!
Autre exemple dictionnaire.items() renvoie une liste de tuple (clef, valeur) :
[ (clef1, valeur1), (clef2, valeur2), ... ]
List/dict comprehensions
Les “list/dict comprehensions” sont des syntaxes particulière permettant de rapidement construire des listes (ou dictionnaires) à partir d’autres structures.
Syntaxe (list comprehension)
[ new_e for e in liste if condition(e) ]
Exemple (list comprehension)
Carré des entiers impairs d’une liste
[ e**2 for e in liste if e % 2 == 1 ]
List/dict comprehensions
Les “list/dict comprehensions” sont des syntaxes particulière permettant de rapidement construire des listes (ou dictionnaires) à partir d’autres structures.
Syntaxe (dict comprehension)
{ new_k:new_v for k, v in d.items() if condition(k, v) }
Exemple (dict comprehension)
{ nom: age-20 for nom, age in ages.items() if age >= 20 }
Générateurs
(Pas vraiment une structure de données, mais c’est lié aux boucles …)
- Une fonction qui renvoie des résultats “au fur et à mesure” qu’ils sont demandés …
- Se comporte comme un itérateur
- Peut ne jamais s’arrêter …!
- Typiquement, évite de créer des listes intermédiaires
exemple SANS generateur
mes_animaux = { "girafe": 300, "coyote": 50,
"chenille": 2, "cobra": 45
# [...]
}
def au_moins_un_metre(animaux):
output = []
for animal, taille in animaux.items():
if taille >= 100:
output.append(animal)
return output
for animal in au_moins_un_metre(mes_animaux):
...
exemple AVEC generateur
mes_animaux = { "girafe": 300, "coyote": 50,
"chenille": 2, "cobra": 45
# [...]
}
def au_moins_un_metre(animaux):
for animal, taille in animaux.items():
if taille >= 100:
yield animal
for animal in au_moins_un_metre(mes_animaux):
...
Il n’est pas nécessaire de créer la liste intermédiaire output
Un autre exemple
def factorielle():
n = 1
acc = 1
while True:
acc *= n
n += 1
yield acc
Ex.7 Structures de données
7.1 : Écrire une fonction qui retourne le plus grand élément d’une liste (ou d’un set) de nombres, et une autre fonction qui retourne le plus petit. Par exemple, plus_grand([5, 9, 12, 6, -1, 4]) retournera 12.
assert plus_grand([5, 9, 12, 6, -1, 4]) == 12
assert plus_grand([-6, -19, -2]) == -2
assert plus_petit([5, 9, 12, 6, -1, 4]) == -1
assert plus_petit([-6, -19, -2]) == -19
7.2 : Écrire une fonction qui retourne le mot le plus long parmis une liste de mot donnée en argument.
assert plus_long(["Paris", "Amsterdam", "Londres"]) == "Amsterdam"
assert plus_long(["Choucroute", "Pizza", "Tarte flambée"]) == "Tarte flambée"
7.3 : Écrire une fonction qui calcule la somme d’une liste de nombres.
assert somme([3, 4, 5]) == 12
assert somme([0, 7, -3]) == 4
7.4 : Écrire une fonction qui prends en argument un chemin de fichier comme “/usr/bin/toto.py” et extrait le nom du fichier, c’est à dire “toto”. On pourra utiliser la méthode chaine.split(caractere) des chaînes de caractère.
7.5.1 : Récuperer le dictionnaire d’exemple auprès du formateur (example_dict.py) et boucler sur ce dictionnaire pour afficher quelque chose comme:
Sebastian est né.e en 1979
Barclay est né.e en 2000
Vivien est né.e en 1955
...
example_dict=[{'name': 'Sebastian', 'email': 'Donec.felis.orci@consectetueripsumnunc.edu', 'country': '1979'}, {'name': 'Barclay', 'email': 'aliquet.metus.urna@neceleifend.co.uk', 'country': '2000'}, {'name': 'Vivien', 'email': 'pharetra@a.com', 'country': '1955'}, {'name': 'Britanney', 'email': 'eu.tellus.Phasellus@arcuvelquam.ca', 'country': '1961'}, {'name': 'Reese', 'email': 'tortor.dictum.eu@egestasSed.ca', 'country': '1951'}, {'name': 'Keegan', 'email': 'libero.nec@cursuset.co.uk', 'country': '1998'}, {'name': 'Ezekiel', 'email': 'tempus.mauris.erat@aclibero.org', 'country': '1951'}, {'name': 'Odessa', 'email': 'massa.Quisque.porttitor@felis.net', 'country': '1925'}, {'name': 'Elijah', 'email': 'luctus.vulputate.nisi@nunc.com', 'country': '1963'}, {'name': 'Hilel', 'email': 'lectus.pede.et@aliquetsem.ca', 'country': '1982'}, {'name': 'Callie', 'email': 'et.euismod.et@aliquetmagnaa.net', 'country': '1984'}, {'name': 'India', 'email': 'Duis.sit.amet@Phaselluslibero.com', 'country': '1938'}, {'name': 'Lane', 'email': 'amet@turpis.ca', 'country': '1922'}, {'name': 'Alexis', 'email': 'sagittis.placerat@nibhdolor.net', 'country': '1927'}, {'name': 'Micah', 'email': 'lorem.eget.mollis@SeddictumProin.com', 'country': '1914'}, {'name': 'Rigel', 'email': 'sollicitudin@eratinconsectetuer.org', 'country': '1941'}, {'name': 'Avram', 'email': 'tincidunt.vehicula@vulputate.org', 'country': '1919'}, {'name': 'Dieter', 'email': 'ornare.lectus.justo@Integeridmagna.org', 'country': '1937'}, {'name': 'Sarah', 'email': 'cubilia.Curae.Phasellus@non.net', 'country': '1946'}, {'name': 'Graham', 'email': 'elit.Curabitur.sed@maurisIntegersem.edu', 'country': '1931'}, {'name': 'Daquan', 'email': 'fermentum.convallis.ligula@porttitorinterdum.co.uk', 'country': '1934'}, {'name': 'Nell', 'email': 'purus@lectusconvallisest.org', 'country': '1997'}, {'name': 'Ocean', 'email': 'ut@Nuncquisarcu.net', 'country': '2006'}, {'name': 'Cruz', 'email': 'Aenean.euismod.mauris@idmollisnec.edu', 'country': '1950'}, {'name': 'Hyacinth', 'email': 'amet@Nunc.edu', 'country': '1929'}]
7.5.2 : Transformer le programme précédent pour n’afficher que les personnes ayant une adresse mail finissant par .edu.
7.6 : Ecrire une fonction compte_lettres qui prends en argument une (grande) chaîne de caractère et retourne un dictionnaire avec un compte des occurences des lettres. Par exemple compte_lettres("hello") retournera {"h":1, "l": 2, "o": 1, "e":1 }. Utiliser cette fonction sur Lorem Ipsum (“Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt […]")
7.7 : Écrire une fonction qui retourne seulement les entiers pairs d’une liste
7.8 : Écrire une fonction qui permet de trier une liste (ou un set) d’entiers
7.9 : En une seule ligne de code, générer la matrice suivante :
[ [ 0, 1, 2, 3, 4 ],
[ 0, 2, 4, 6, 8 ],
[ 0, 3, 6, 9, 12 ],
[ 0, 4, 8, 12, 16 ] ]
7.10 : Réécrire la fonction somme du 8.2, mais cette fois sans utiliser de variable intermédiaire (utiliser la récursivité)
7.11 : Ecrire un générateur carre() qui genere la suite 1, 4, 9, 16, … Utiliser ce générateur pour afficher les carrés jusqu’à ce qu’une valeur dépasse 200.
7.12 : Ecrire un générateur fibonnaci qui genere la suite de fibonnaci 0, 1, 1, 2, 3, 5, 8, … Utiliser ce générateur pour afficher les valeurs jusqu’à ce qu’elles dépassent 500.
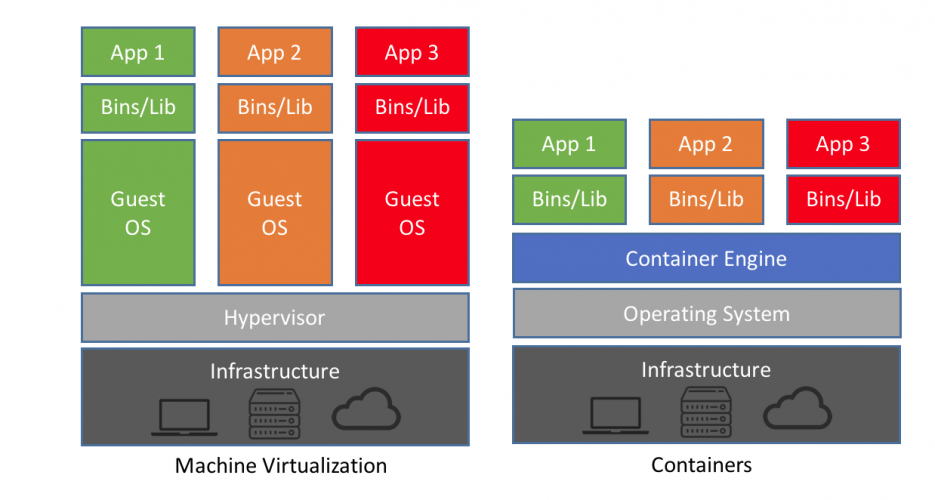
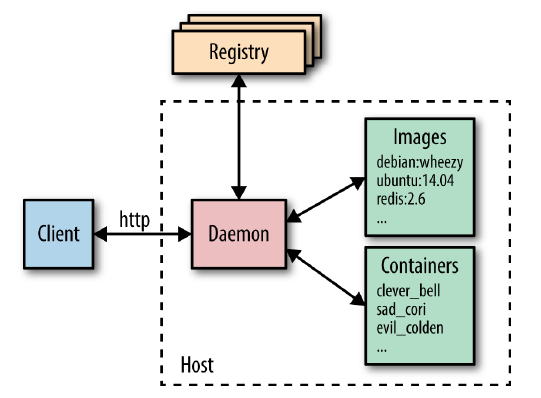
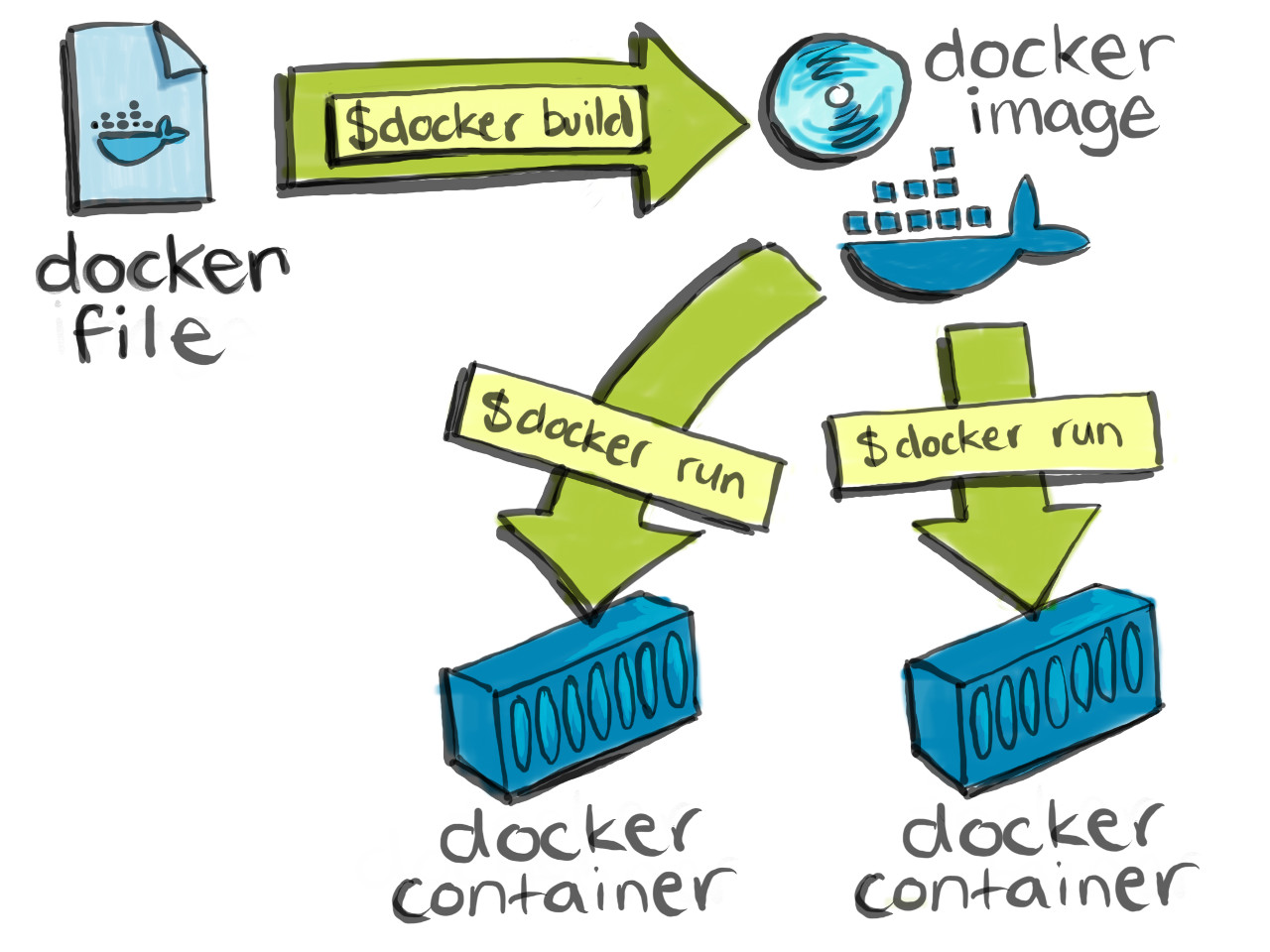 Docker possède à la fois un module pour lancer les applications (runtime) et un outil de build d’application.
Docker possède à la fois un module pour lancer les applications (runtime) et un outil de build d’application.
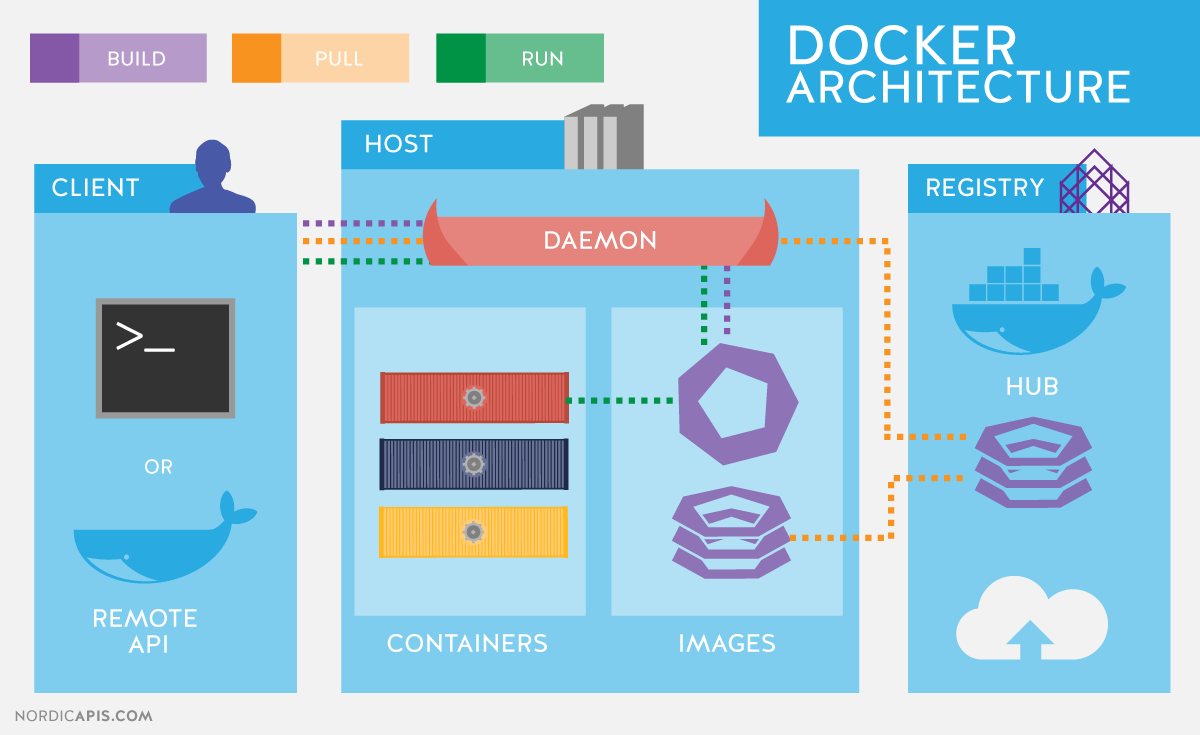
 Il faut aussi prendre l’habitude de bien lire ce que la console indique après avoir passé vos commandes.
Il faut aussi prendre l’habitude de bien lire ce que la console indique après avoir passé vos commandes.


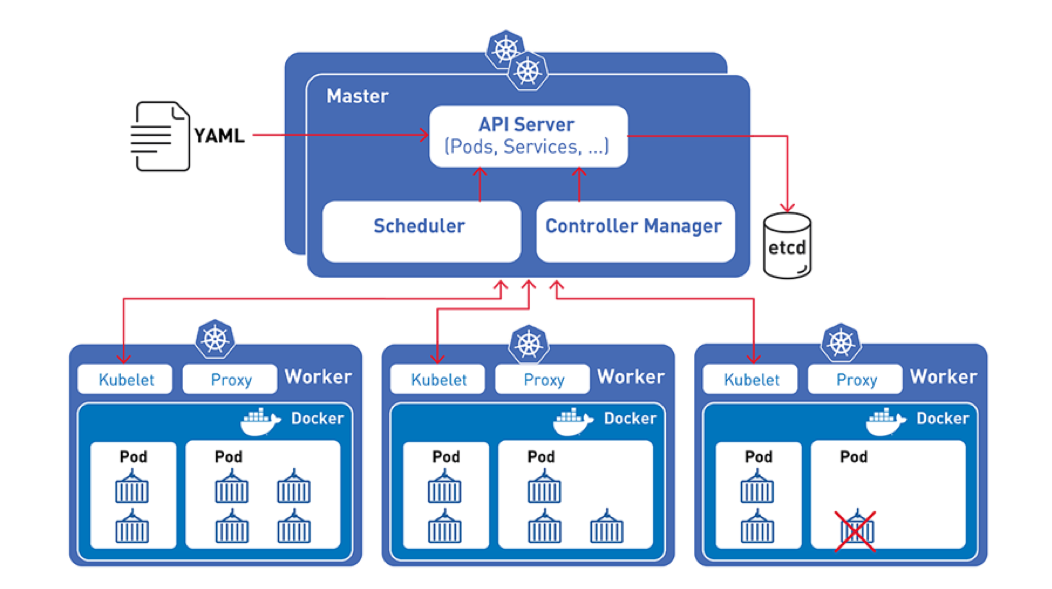

















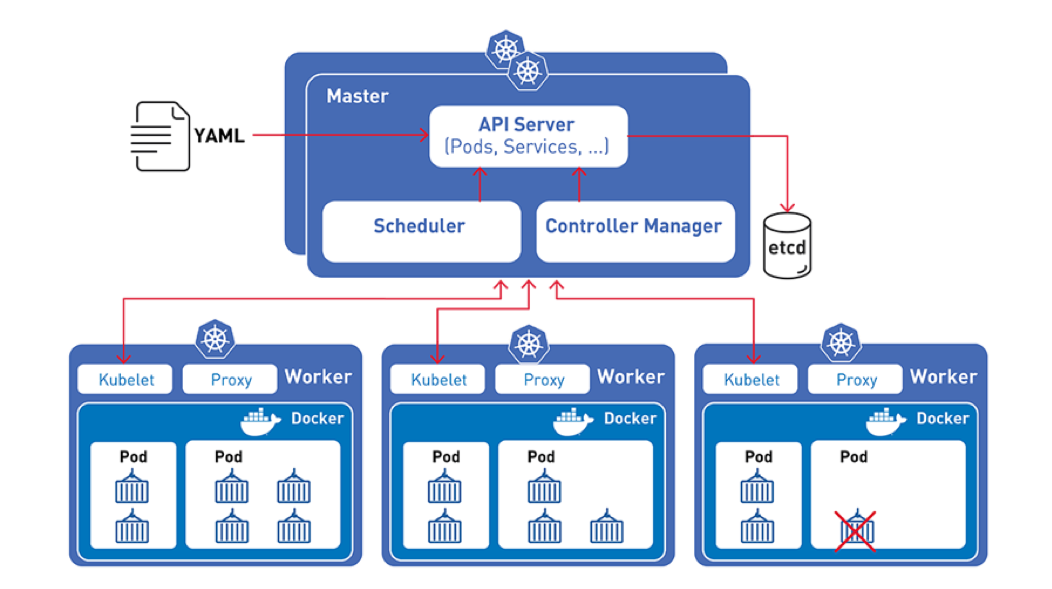
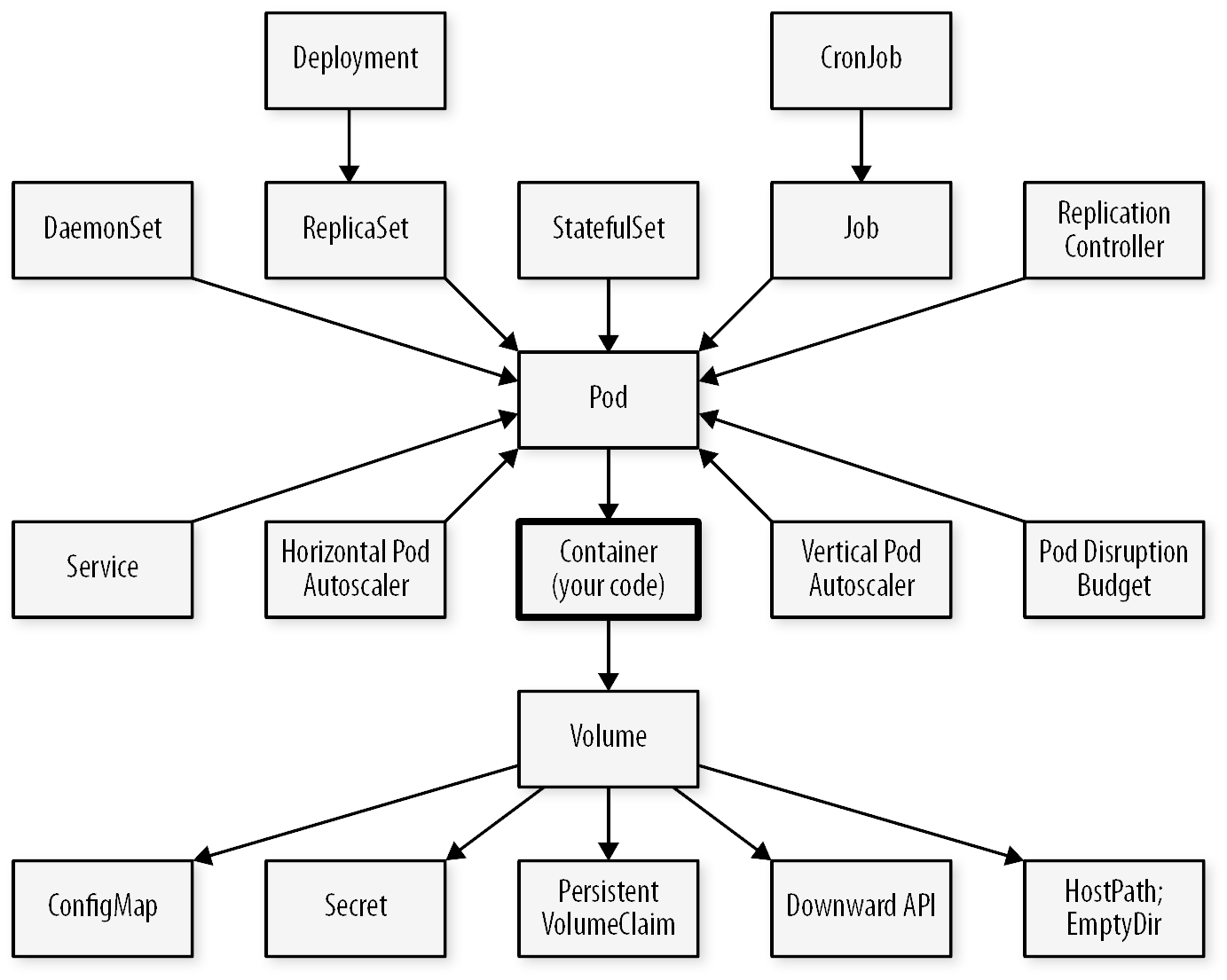

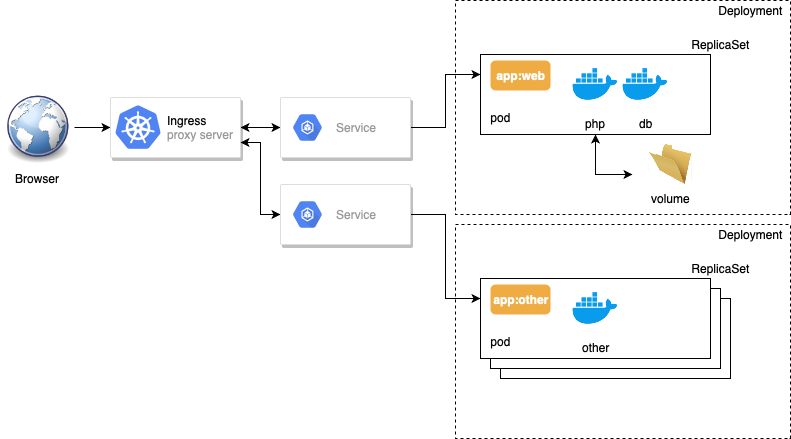
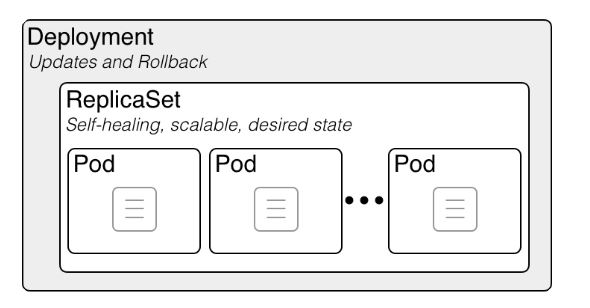 Les poupées russes Kubernetes : un Deployment contient un ReplicaSet, qui contient des Pods, qui contiennent des conteneurs
Les poupées russes Kubernetes : un Deployment contient un ReplicaSet, qui contient des Pods, qui contiennent des conteneurs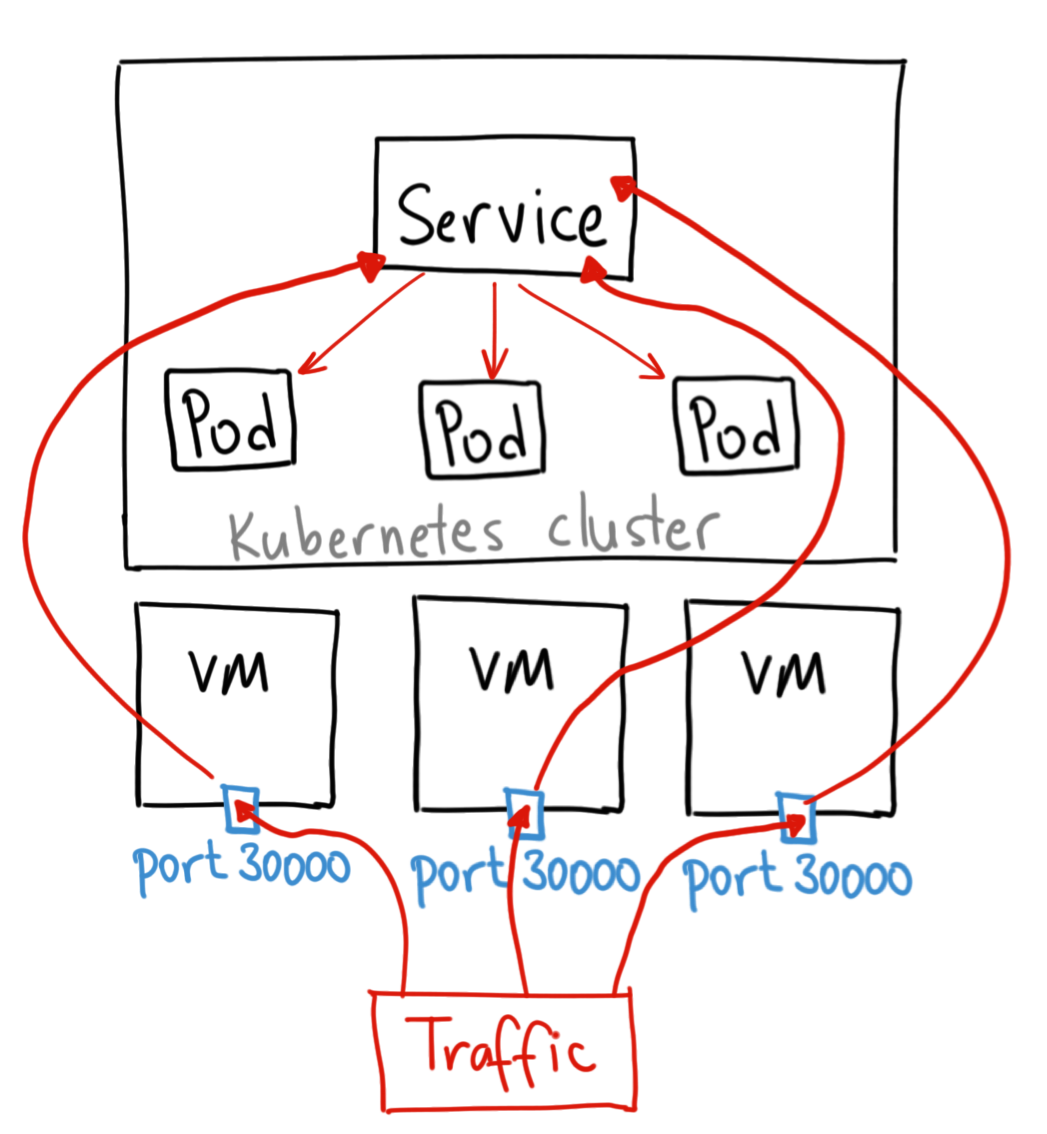 Crédits à
Crédits à 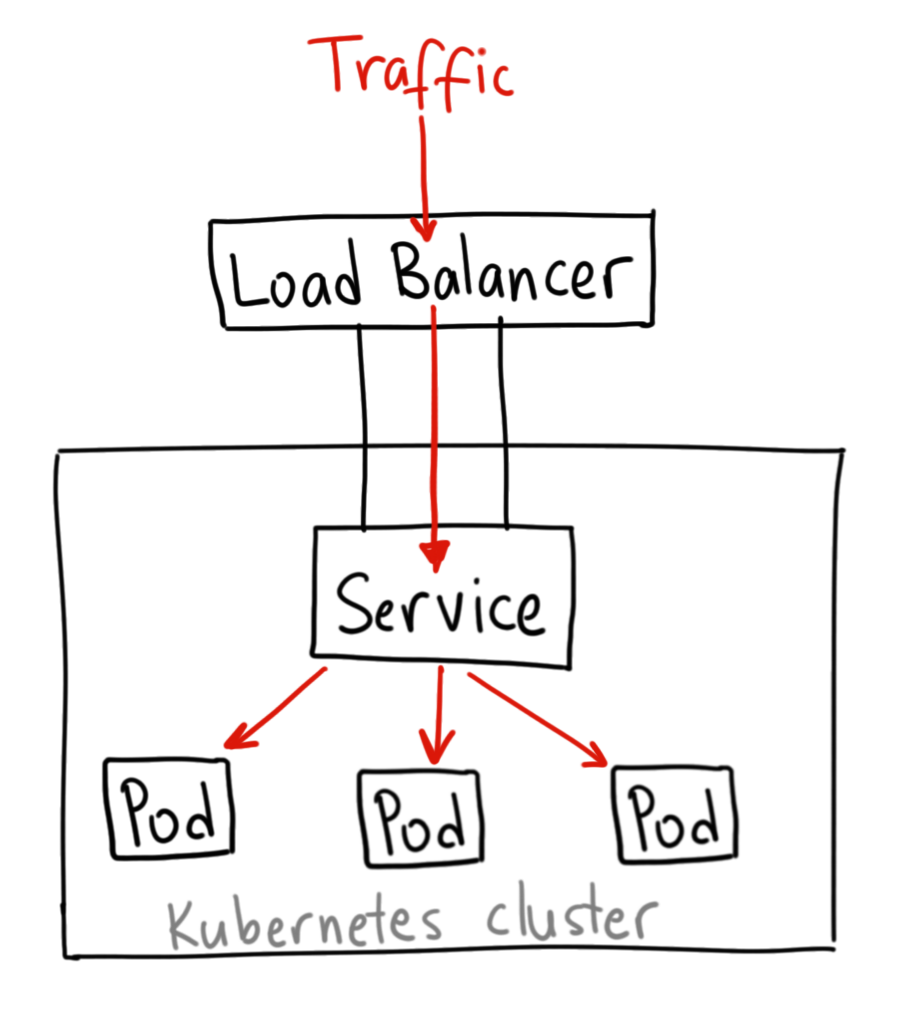 Crédits
Crédits 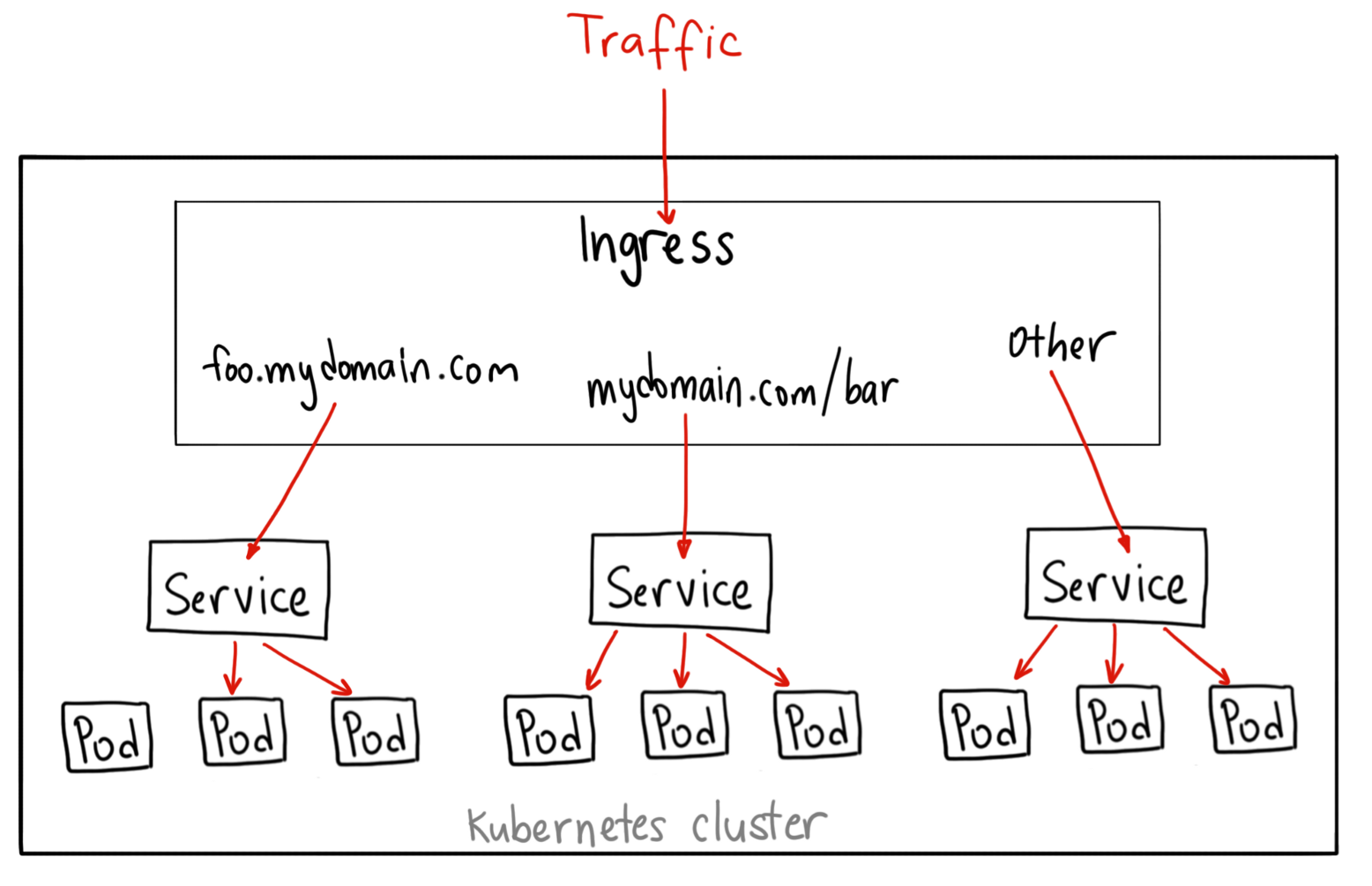 Crédits
Crédits 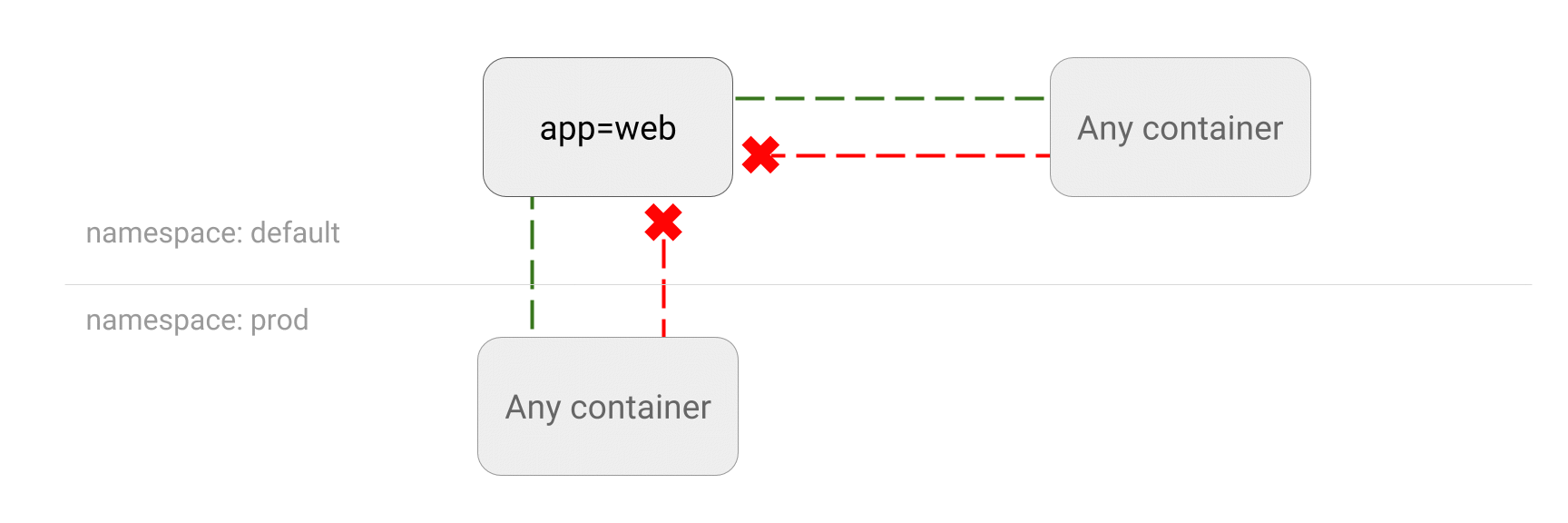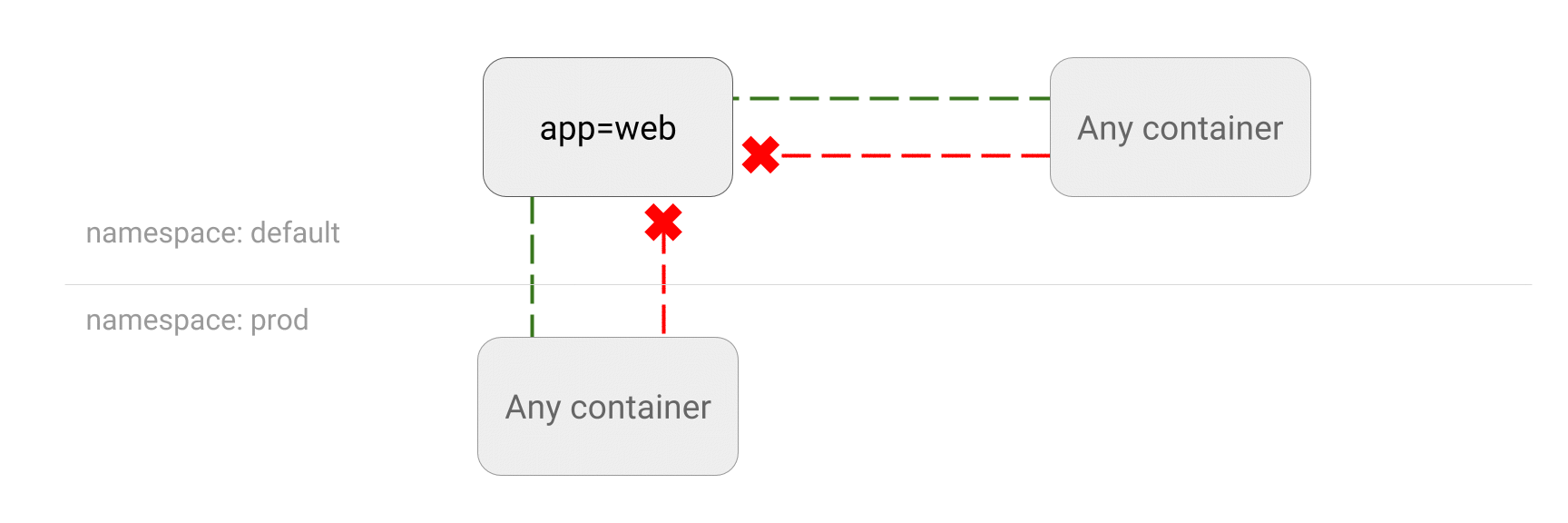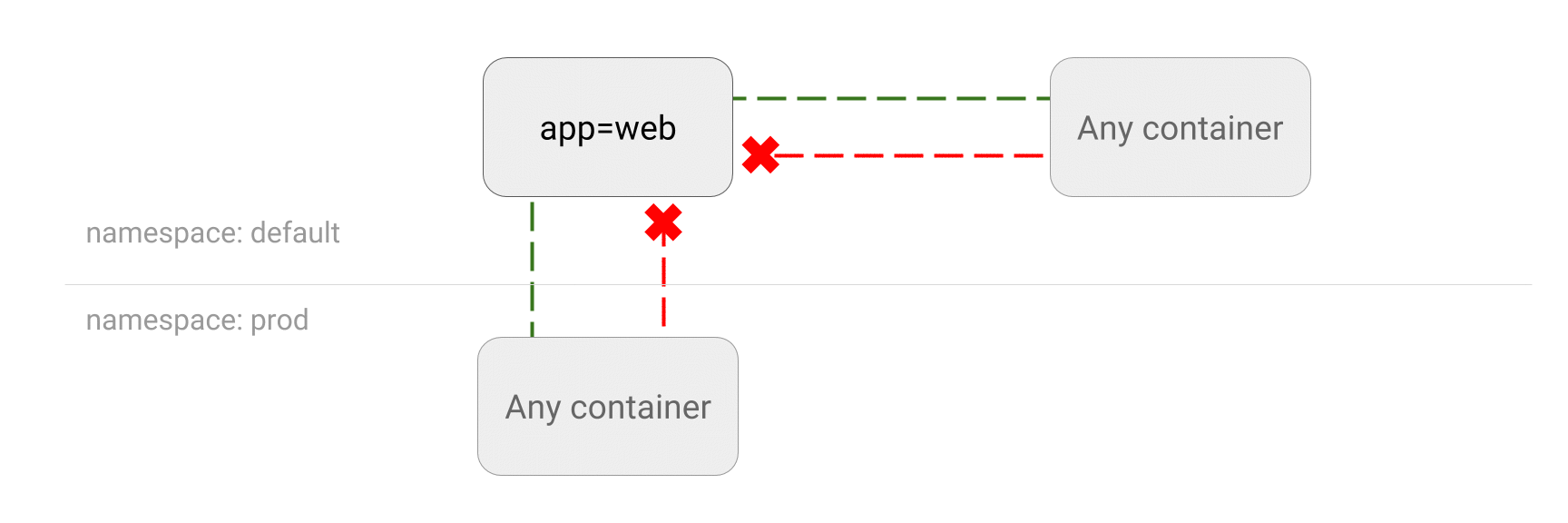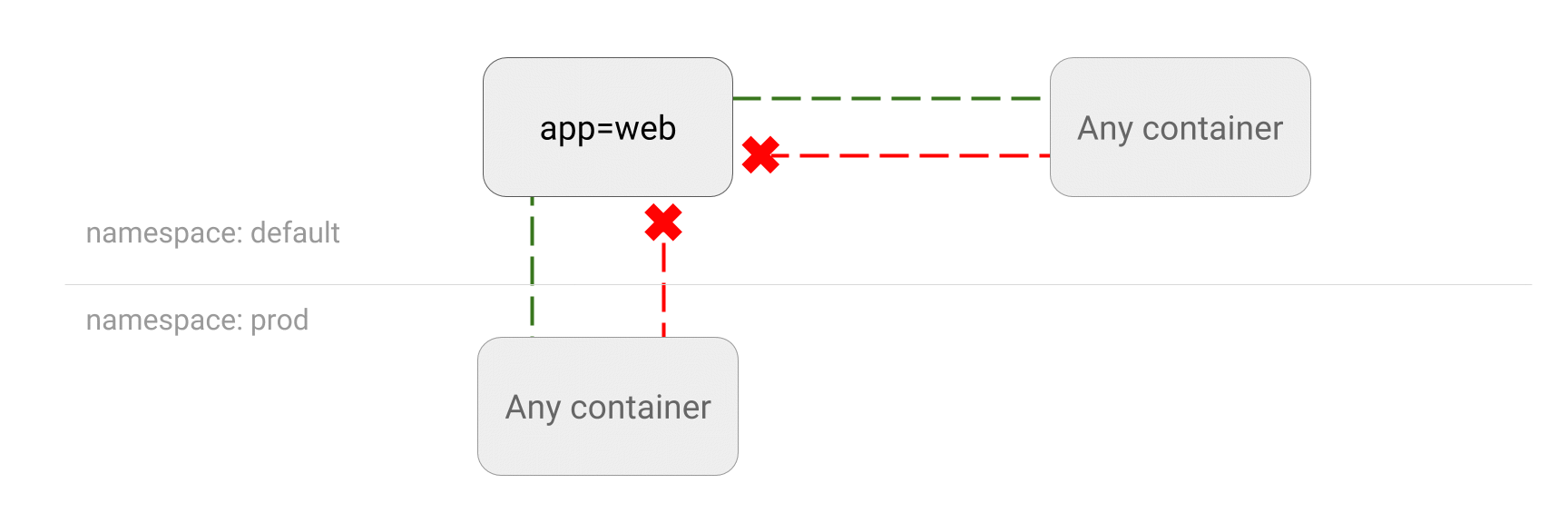 Crédits
Crédits 

{kind=link}