Introduction DevOps
La culture et la pratique du DevOps
A propos de moi
A propos de vous
- “Profil” : votre environnement technique initial
- Besoins : ce que vous aimeriez faire, avez besoin de savoir faire
- Attentes de cette formation
DevOps : définition
“Le DevOps est un mouvement qui s’attaque au conflit existant structurellement entre le développement de logiciels et les opérations. Ce conflit résulte d’objectifs et de motivations divergents. Le DevOps améliore la collaboration entre les départements du développement et des opérations et rationalise l’ensemble de l’organisation. (Citation de Hütterman 2012 - Devops for developers)”
L’agilité en informatique
-
Traditionnellement la qualité logicielle provient :
- d’une conception détaillée en amont = création d’un spécification détaillée
- d’un contrôle de qualité humain avant chaque livraison logicielle basé sur une processus = vérification du logiciel par rapport à la spécification
-
Problèmes historiques posé par trop de spécification et validation humaine :
- Lenteur de livraison du logiciel (une version par an ?) donc aussi difficulté de fixer les bugs et problèmes de sécurité a temps
- Le travail des développeur·euses est dominé par des
processformels : ennuyeux et abstrait - difficulté commerciale : comment répondre à la concurence s’il faut 3 ans pour lancer un produit logiciel.
Solution : développer de façon agile c’est à dire itérative
- Sortir une version par semaine voir par jour
- Créer de petites évolution plutôt que de grosses évolution
- Confronter en permanence le logiciel aux retours clients et utilisateurs
Mais l’agilité traditionnelle ne concerne pas l’administration système.
La motivation au coeur du DevOps : La célérité
- La célérité est : la rapidité (itérative) non pas seulement dans le développement du logiciel mais plus largement dans la livraison du service au client:
Exemple : Netflix ou Spotify ou Facebook etc. déploient une nouvelle version mineure de leur logiciel par jour.
- Lorsque la concurrence peut déployer des innovations en continu il devient central de pouvoir le faire.
Le problème que cherche à résoudre le DevOps
La célérité et l’agrandissementest sont incompatibles avec une administration système traditionnelle:
Dans un DSI (département de service informatique) on organise ces activités d’admin sys en opérations:
- On a un planning d’opération avec les priorités du moment et les trucs moins urgents
- On prépare chaque opération au minimum quelques jours à l’avance.
- On suit un protocole pour pas oublier des étapes de l’opération (pas oublier de faire une sauvegarde avant par exemple)
La difficulté principale pour les Ops c’est qu’un système informatique est:
- Un système très complexe qu’il est quasi impossible de complètement visualiser dans sa tête.
- Les évènements qui se passe sur la machines sont instantanés et invisibles
- L'état actuel de la machine n’est pas ou peu explicite (combien d’utilisateur, machine pas connectée au réseau par exemple.)
- Les interactions entre des problèmes peu graves peuvent entrainer des erreurs critiques en cascades.
On peut donc constater que les opérations traditionnelles implique une culture de la prudence
- On s’organise à l’avance.
- On vérifie plusieurs fois chaque chose.
- On ne fait pas confiance au code que nous donnent les développeur·euses.
- On suit des procédures pour limiter les risques.
- On surveille l’état du système (on parle de monitoring)
- Et on reçoit même des SMS la nuit si ya un problème :S
Bilan
Les opérations “traditionnelles”:
- Peuvent pas aller trop vite car il faut marcher sur des oeufs.
- Les Ops veulent pas déployer de nouvelles versions trop souvent car ça fait plein de boulot et ils prennent des risques (bugs / incompatilibités).
- Quand c’est mal organisé ou qu’on va trop vite il y a des catastrophes possibles.
L’objectif technique idéal du DevOps : Intégration et déploiement continus (CI/CD)
Du côté des développeur·euses avec l’agilité on a déjà depuis des années une façon d’automatiser pleins d’opérations sur le code à chaque fois qu’on valide une modification.
- Chaque modification du code est validée dans le gestionnaire de version Git.
- Ensuite est envoyée sur le dépot de code commun.
- Des tests logiciels se lancent automatiquement pour s’assurer qu’il n’y a pas de bugs ou de failles.
- Les développeur·euses sont avertis des problèmes.
C’est ce qu’on appelle l’intégration continue.
Le principe central du DevOps est d’automatiser également les opérations de déploiement et de maintenance en se basant sur le même modèle.
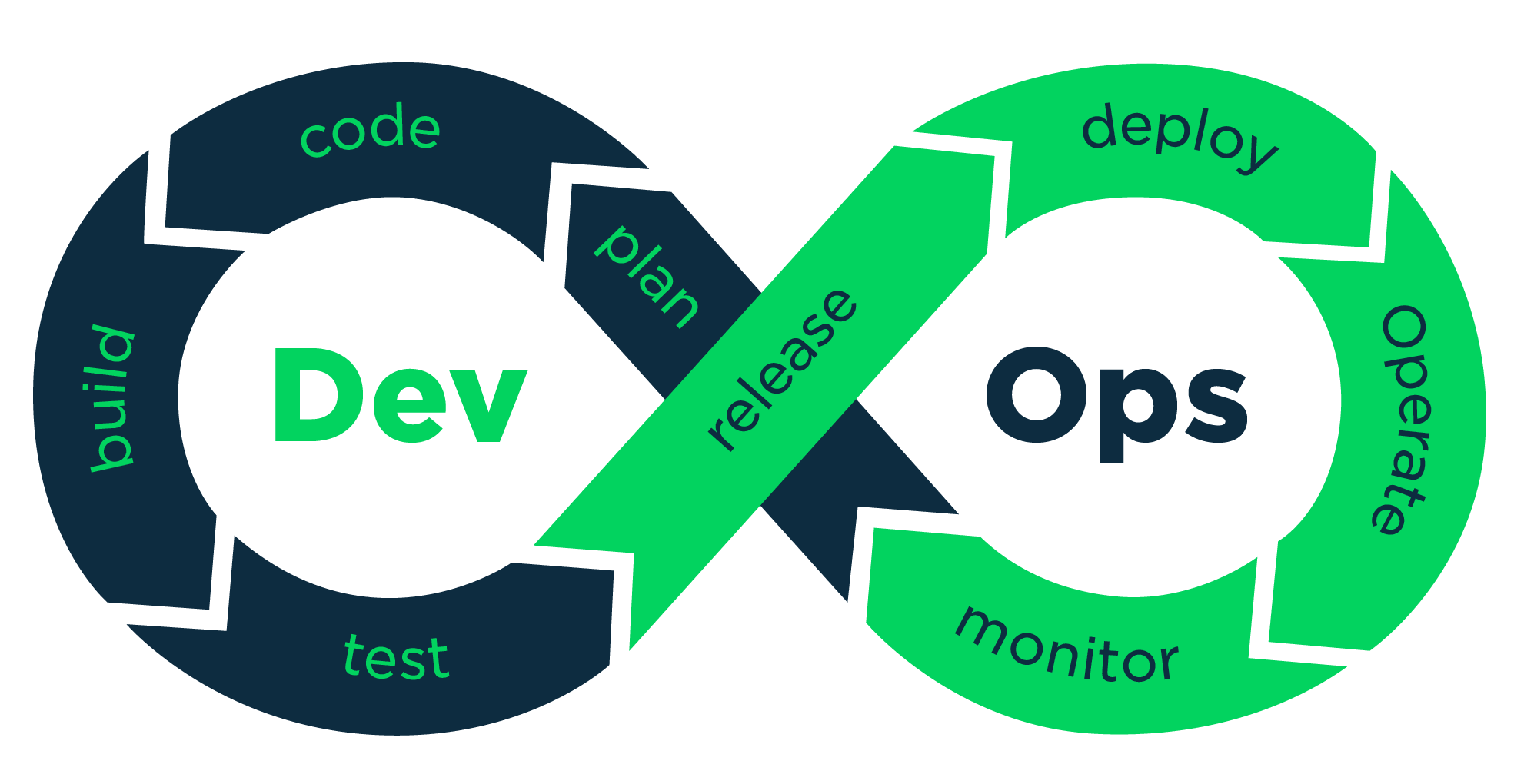
Mais pour que ça fonctionne il faut résoudre des défi techniques nouveau => innovations
Renforcer la collaboration
Équipes transversales
Dans le cadre d’un produit logiciel, les administrateurs systèmes sont rassemblées avec le développement et le chef produit : tout le monde fait les réunions ensemble pour se parler et se comprendre.
Culture de la polyvalence
-
Les développeur·euses peuvent plus facilement créer un environnement réaliste pour jouer avec et comprendre comment fonctionne l’infrastructure de production (ils progressent dans l’administration système et la compréhension des enjeux opérationnels).
-
Les adminsys apprennent à programmer leurs opérations de façon puissante il deviennent donc plus proche de la logique des développeur·euses. (grace à l’Infrastructure as Code)
Le profil DevOps
Par abus de langage on dit un ou une DevOps pour parler d’un métier spécifique dans une entreprise. Je dis que je suis DevOps sur mon CV par exemple.
Vous pouvez retenir :
Un·e DevOps c’est un·e Administrateur·ice Système qui programme ses outils.
Le profil DevOps
Il faut être polyvalent : bien connaître l’administration système Linux mais aussi un peu la programmation et le développement.
Il faut connaître les nouvelles bonnes pratiques et les nouveaux outils cités précédemment.
En résumé
- Un profil ? Un hybride de dev et d’ops…
- Une méthode ? Infra-as-Code, continuous integration and delivery (CI/CD), conteneurisation
- Une façon de virer des adminsys… ?
Réancrer les programmes dans la réalité de leur utilisation
“Machines ain’t smart. You are!” Comment dire correctement aux machines quoi faire ?
Solutions techniques
Quelques expressions que vous allez beaucoup entendre:
- Technologies de Cloud (infrastructures à la demande)
- CI / CD
- Infrastructure as Code
- Containerisation
Le cloud
Plutôt que d'installer manuellement de nouveaux serveurs linux pour faire tourner des logiciels on peut utiliser des outils pour faire apparaître de nouveaux serveurs à la demande.
Du coup on peut agrandir sans effort l’infrastructure de production pour délivrer une nouvelle version
C’est ce qu’on appelle le IaaS (Infrastructure as a service)
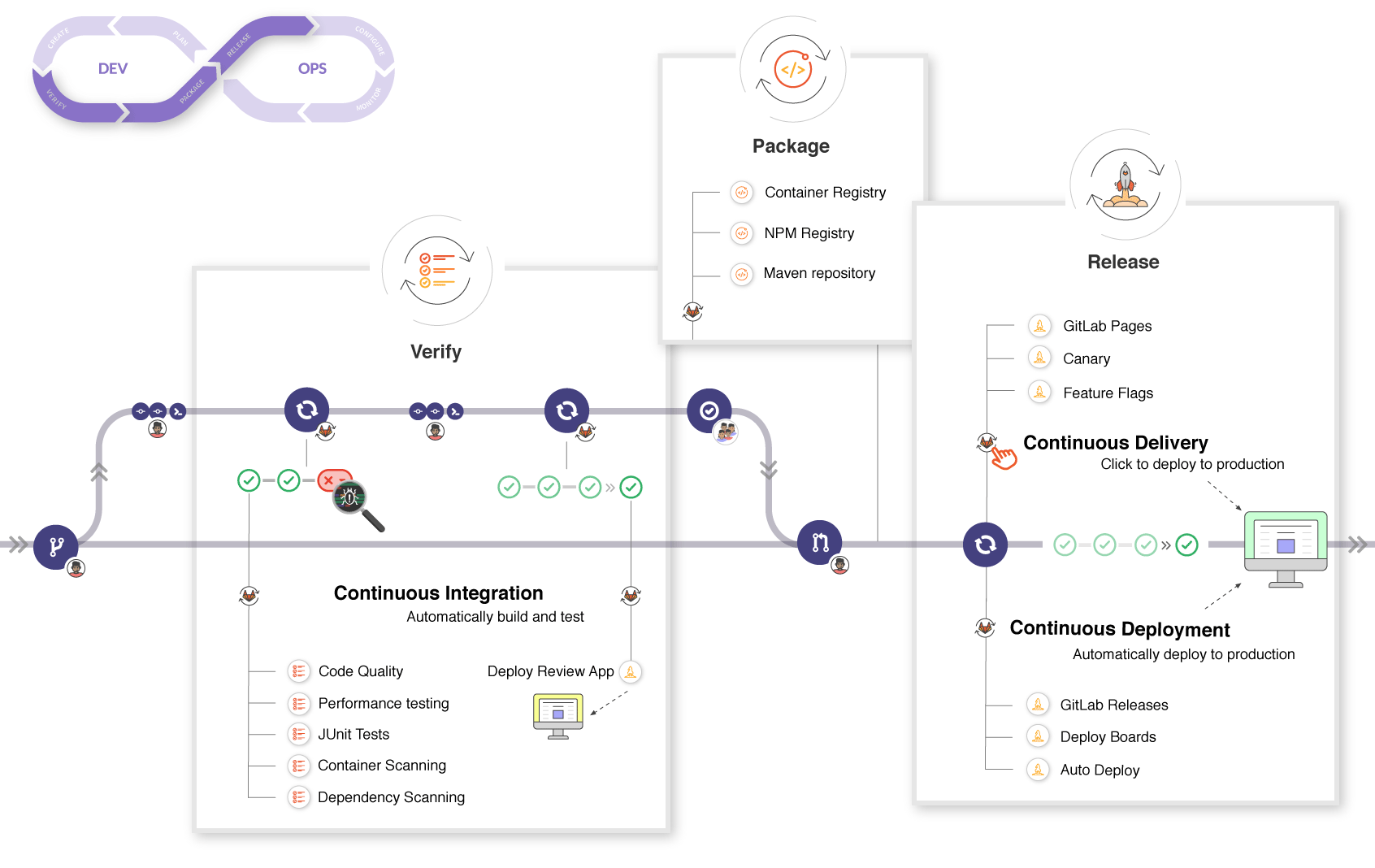
CI / CD
(intégration continue et déploiement continu)
-
Accélérer la livraison des nouvelles versions du logiciel.
-
Des tests systématiques et automatisés pour ne pas se reposer sur la vérification humaine.
-
Un déploiement progressif en parallèle (Blue/Green) pour pouvoir automatiser le Rollback et être serein.
-
A chaque étape le code passe dans un Pipeline de validation automatique.
Infrastructure as code
-
Permet de régler un problème de l’administration système : Difficulté de connaître l’état du système à un instant T, ce qui augmente les risques.
-
Plutôt que d’appliquer des commandes puis d’oublier si on les a appliquées, On décrit le système d’exploitation (l’état du linux) dans un fichier et on utilise un système qui applique cette configuration explicite à tout moment.
-
Permet aux Ops/AdminSys de travailler comme des développeur·euses (avec une usine logicielle et ses outils)
Infrastructure As Code
Un mouvement d’informatique lié au DevOps et au cloud :
- Rapprocher la production logicielle et la gestion de l’infrastructure
- Rapprocher la configuration de dev et de production (+ staging)
- Assumer le côté imprévisible de l’informatique en ayant une approche expérimentale
- Aller vers de l’intégration et du déploiement continu et automatisé.
Une façon de définir une infrastructure dans un fichier descriptif et ainsi de créer dynamiquement des services.
- Du code qui décrit l’état désiré d’un système.
- Arrêtons de faire de l’admin-sys ad-hoc !
Avantages :
- Descriptif : on peut lire facilement l'état actuel de l’infra
- Git ! Gérer les versions de l’infrastructure et collaborer facilement comme avec du code.
- Tester les instrastructure pour éviter les régressions/bugs
- Facilite l’intégration et le déploiement continus = vélocité = versions testées puis mises en prod' progressivement et automatiquement dans le cycle DevOps
- Pas de surprise = possibilité d’agrandir les clusters sans souci !
- On peut multiplier les machines (une machine ou 100 machines identiques c’est pareil).
Assez différent de l’administration système sur mesure (= méthode de résolution plus ou moins rigoureuse à chaque nouveau bug)
Infrastructure As Code
Concepts proches
-
Infrastructure as a Service (commercial et logiciel)
- Amazon Web Services, Azure, Google Cloud, DigitalOcean
- = des VM ou des serveurs dédiés
-
Plateform as a Service - Heroku, cluster Kubernetes Avec une offre d’hébergement de conteneurs, on parle la plupart du temps de Platform as a Service.
L’infrastructure as code
Il s’agit comme son nom l’indique de gérer les infrastructures en tant que code c’est-à-dire des fichiers textes avec une logique algorithmique/de données et suivis grâce à un gestionnaire de version (git).
Le problème identifié que cherche a résoudre l’IaC est un écheveau de difficulées pratiques rencontrée dans l’administration système traditionnelle:
- Connaissance limité de l’état courant d’un système lorsqu’on fait de l'administration ad-hoc (manuelle avec des commandes unix/dos).
- Dérive progressive de l’état des systèmes et difficultés à documenter leur états.
- Fiabilité limitée et risques peu maîtrisés lors de certaines opérations transversales (si d’autres méchanismes de fiabilisation n’ont pas été mis en place).
- Problème de communication dans les grandes équipes car l’information est détenue implicitement par quelques personnes.
- Faible reproductibilité des systèmes et donc difficulté/lenteur du passage à l’échelle (horizontal scaling).
- Multiplier les serveurs identiques est difficile si leur état est le résultat d’un processus manuel partiellement documenté.
- Difficulté à reproduire/simuler l’état précis de l’infrastructure de production dans les contextes de tests logiciels.
- Difficultés du travail collaboratif dans de grandes équipes avec plusieurs culture (Dev vs Ops) lorsque les rythmes et les modes de travail diffèrent
- L’IaC permet de tout gérer avec git et des commits.
- L’IaC permet aux Ops qui ne le faisait pas de se mettre au code et aux développeur·euses de se confronter plus facilement.
- L’IaC permet d’accélérer la transformation des infrastructures pour l’aligner sur la livraison logicielle quotidienne (idéalement ;) )
Containerisation
Les conteneurs (Docker et Kubernetes)
Faire des boîtes isolées avec nos logiciels:
- Un façon standard de packager un logiciel
- Cela permet d’assembler de grosses applications comme des legos
- Cela réduit la complexité grâce:
- à l’intégration de toutes les dépendance déjà dans la boîte
- au principe d’immutabilité qui implique de jeter les boîtes (automatiser pour lutter contre la culture prudence). Rend l’infra prédictible.
Docker (et un peu LXC)
Il s’agit de mettre en quelques sortes les logiciels dans des boîtes :
-
Avec tout ce qu’il faut pour qu’il fonctionnent (leurs dépendances).
-
Ces boîtes sont fermées (on peut ne peux plus les modifier). On parle d'immutabilité.
-
Si on a besoin d’un nouvelle version on fait un nouveau modèle de boîte. (on dit une nouvelle image docker)
-
Cette nouvelle image permet de créer autant d’instances que nécessaire.
Containerisation - Pourquoi ?
-
L’isolation des containers permet d’éviter que les logiciels s’emmêlent entre eux. (Les dépendances ne rentrent pas en conflit)
-
Les conteneurs non modifiables permettent de savoir exactement l’état de ce qu’on exécute sur l’ordinateur
Le risque de bug diminue énormément : fiabilisation
- L’agrandissement d’un infrastructure logiciel est beaucoup pour facile lorsqu’on a des boîtes autonomes qu’on peut multiplier.