1 - Découverte de l'écosystème Elastic
Apprendre à nager dans un océan d’évènements et de texte!
- Ouvrage recommandé : PacktPub - Learning Elastic Stack 6
Dans les épisodes précédents
- Linux ? on va reparler de tail, grep et des logs
- HTTP ? on va utiliser une API REST (basé sur HTTP)
- JSON ? on va utiliser des documents formatés en JSON
- Les bases de données ?
- Machines virtuelles ? on va parler un peu à la fin de cluster dans le cloud (c’est compliqué un cluster elasticsearch mais on va surtout voir ça théoriquement)
Rappel
- L’informatique c’est complexe surtout lorsqu’on est pas familier avec l’environnement. Ça prend quelques temps pour être vraiment à l’aise.
- Elasticsearch et sa stack c’est particulièrement compliqué ! J’ai essayé d’évité les détails inutiles.
- Je peux oublier de préciser certaines choses donc arrêtez moi si ce que je dis n’est pas clair.
Intro) La stack ELK : Chercher et analyser les logs de façon centralisée
ELK : Elasticsearch, Logstash, Kibana
-
Elasticsearch : une base de données pour stocker des grandes quantités de documents texte et chercher dedans.
-
Logstash : Un collecteur de logs et autre données pour remplir Elasticsearch.
-
Kibana : Une interface web pratique pour chercher et analyser les données stockées.
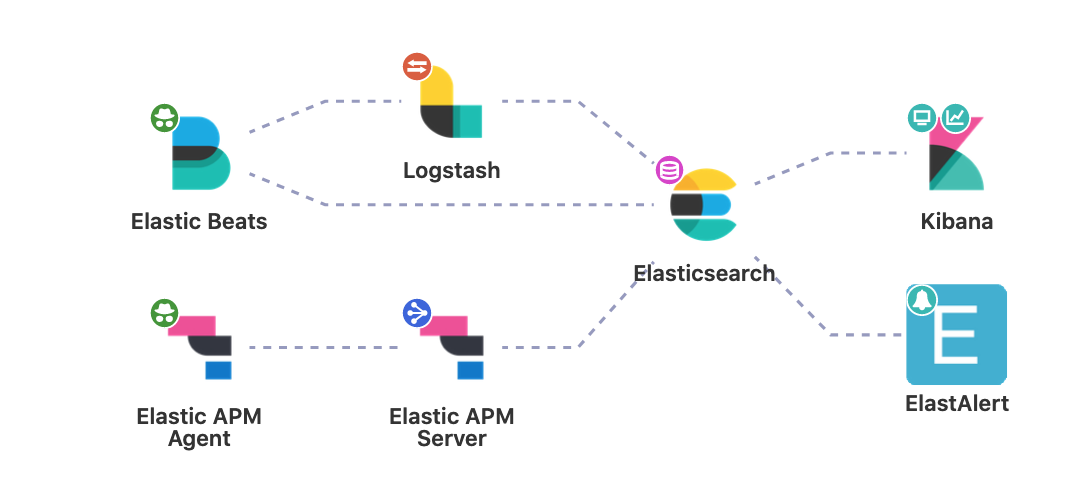
La suite Elastic
La suite Elastic, historiquement appelée “ELK”, est une combinaison de plusieurs produits de la société Elastic, qui développe des logiciels :
- de base de données distribuée (Elasticsearch)
- de dashboard / d’interface graphique pour explorer des données (Kibana)
- de logging / monitoring (Logstash et Beats)
Elastic APM
APM est le petit dernier d’Elastic, axé sur le monitoring et le traçage des performances des applications.
L’écosystème Elastic
La société Elastic évolue assez vite et change souvent ses produits. Elle a un business model open core : les fonctionnalités de base sont gratuites et open source, certaines ont une licence gratuites et source ouverte un peu spéciale et sont regroupées dans le “X-Pack” (les fonctionnalités Basic). D’autres fonctionnalités “X-Pack” enfin nécessitent un abonnement “Gold” ou plus.
Le cœur des produits Elastic est composé de Elasticsearch, Kibana (les dashboards et le mode Discover), de Logstash et de Filebeat.
Des bagarres de licence ont conduit d’autres personnes à proposer un fork d’Elasticsearch : OpenSearch (anciennement OpenDistro for Elasticsearch) qui est un fork de la suite Elastic, sponsorisé par Amazon et AWS.
Détails : https://www.elastic.co/fr/subscriptions
Pourquoi ELK ? Pourquoi c’est dans le cursus
- Gérer une GRANDE quantité de logs sur une infrastructure (entre 5 et des centaines de machines)
- Les explorer efficacement : un problème difficile vu la quantité (on y reviendra)
- Un brique important pour avoir des applications distribuées avec un déploiement automatisé #Devops
En résumé
- On va voir trois choses durant ces deux jours qui peuvent résumer l’intérêt d’ELK:
- Les logs : pourquoi? comment ? ( quelle est la motivation de ELK )
- Découvrir elasticsearch et comment chercher dans du texte ? ( la partie principale )
- Qu’est-ce qu’une infra distribuée moderne ? pourquoi ELK c’est du devops ? ( fin )
Ce qu’on ne va que mentionner rapidement
- Voir en détail l’installation d’une stack ELK à la main
- Configurer Logstash ou Elastic APM pour pomper des logs d’une vraie infrastructure
- Aborder la sécurité de ELK dans sa totalité parce que c’est compliqué (mais c’est important pour faire de vraies installations)
Rapidement, la sécurité dans Elasticsearch
L’écrasante majorité des piratages de Elasticsearch vient simplement de l’exposition sans mot de passe d’instances Elasticsearch sur des adresses IP publiques. Pour s’en rendre compte, on peut demander au moteur de recherche Shodan la liste des serveurs qui ont le port 9200 ouvert sur Internet et qui ne demandent pas d’authentification.
Il y a un modèle RBAC (qui a droit de faire quoi sur le cluster) qui est assez complet et permet aux admins Elasticsearch de mettre en place une gestion des droits assez fine.
La “hype” Elasticsearch
- Indipensable à de plus en plus d’entreprises qui grossissent : pour augmenter le contrôle sur les infrastructures.
- Un outil très versatile et bien fait qui permet de faire de jolis dashboards d’analyse et les gens adorent avoir des jolis dashboards
- Utile pour faire des big data : c’est un peu le moteur de l’informatique actuelle. Tous les nouveaux services fonctionnent grace au traitement de données.
Dashboards
I) Les évènements d’un système et le logging
I.1) Rappel - pourquoi des Logs ?
Logs ?
- Ça veut dire journaux (système) et bûches
- Icone originale de Logstash:

Comprendre ce qui se trame
- Prendre connaissance et analyser les évènements d’un système d’un point de vue opérationnel.
- Les évènements en informatique sont invisibles et presque instantanés.
- Les journaux sont la façon la plus simple de contrôler ce qui se passe
- Des fichiers textes simple avec une ligne par évènement
Objectif 1: monitoring
- Suivre et anticiper le fonctionnement d’un système:
- suivre (et réparer) = zut j’ai une erreur : le service nginx a crashé sur mon infra
- anticiper : le disque dur de cette machine sera bientôt plein il faut que je le change / le vide.
- enquêter : par exemple sur les erreurs rares d’une application
Objectif 2 : conserver les traces de ces évènements pour analyse
-
Archiver pour analyser sur la longue durée (6 mois à 1 an ?) avec des graphiques.
-
Exemples : ces derniers mois est-ce que l’application a correctement répondu aux requêtes de mes utilisateurs ?
- Compter le nombre de timeout (application est trop lente ?)
- Compter le nombre de requêtes pour savoir quand sont les pics d’usage dans la journée
- Connaître la provenance des requêtes et le délai de réponse pour savoir
- si les serveurs sont correctement disposés géographiquement.
- si les requêtes sont “routées” (redirigées) vers le bon serveur.
Infra distribuée
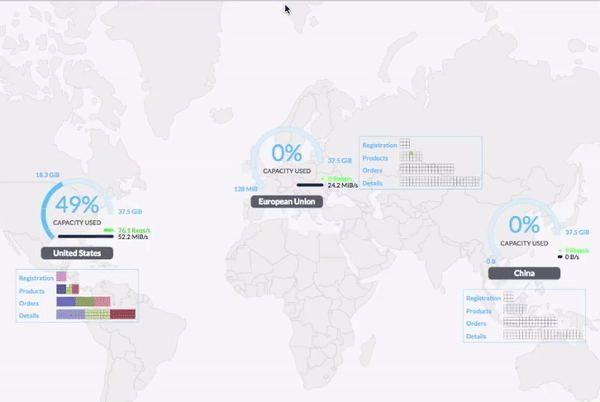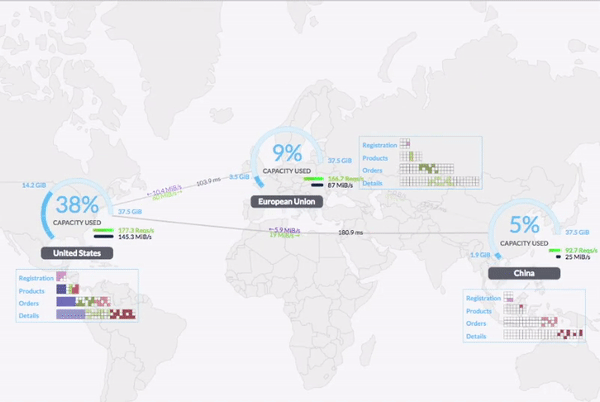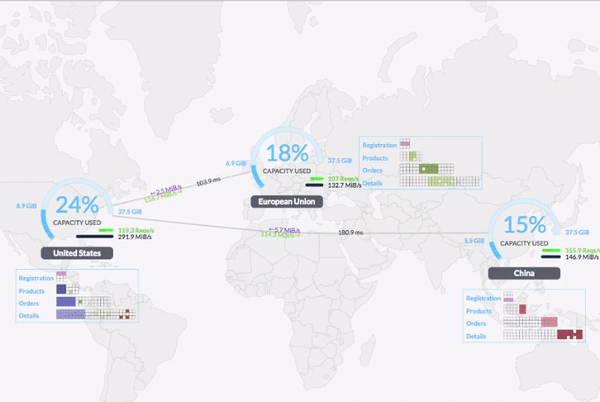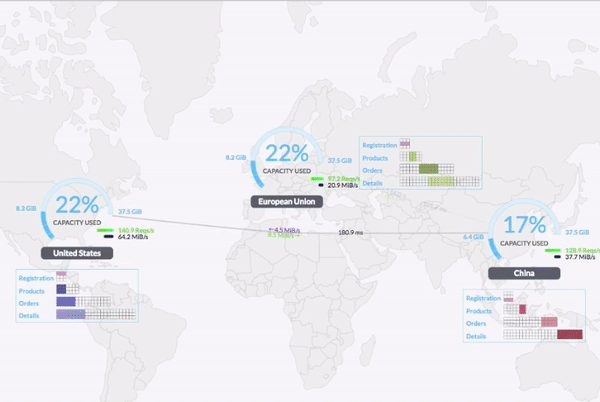
Exemples de fichier de logs
- chaque application peut avoir un fichier de log
- ou alors on peut les rassembler dans un le même fichier
- les logs sont dans
/var/log
Vous en connaissez ?
Exemples de fichier de logs
Exemples de fichiers de logs :
auth.log: connexion des utilisateurs au systèmehttpd.log: connexion au serveur web apachemail.log: aussi bien envoi que réception de mailsnginx/access.log: connexion au serveur web nginxnginx/error.log: erreurs de connexion au serveur web nginx
Exemple d’investigation
Objectif:
- analyser des logs pour retrouver une information
- être attentif-ve au format des logs
Sur le serveur exemple.net, une page web a été supprimée. On veut savoir qui des trois administrateurs Alice, Bob ou Jack a fait cette modification.
- On se connecte en SSH
- en utilisant
catetgreppar exemple :
- Pour connaître le titre du site au fil du temps consultez le fichier
/var/log/nginx/access.log - on utilise
| grep 403et| grep 200pour savoir quand la page a disparu (en cherchant les codes d’erreur HTTP) - Pour savoir qui s’est connecté on consulte le fichier
/var/log/auth.log - on utilise
| grepet l’heure pour savoir qui s’est connecté à cette heure ci
Bilan
- Explorer les logs “à la main” c’est pas toujours très pratique.
- Chercher des évènements datés en filtrant n’est pas très adapté.
- Résoudre un problème nécessite de les interpréter.
- Pour cela on doit chercher et croiser des informations diverses avec un but.
I.2) Le problème avec les logs d’une infrastructure
Décentralisé
-
Une infrastructure c’est beaucoup de machines: les logs sont décentralisés à plein d’endroits.
- Au delà de 3 machines pas question de se logguer sur chacune pour enquêter.
-
On veut un endroit centralisé pour tout ranger.
La quantité
- Des millions et des millions de ligne de journaux, ce qui représente potentiellement des teraoctets de données.
- Cette quantité faramineuse de données texte il faut pouvoir:
- la stocker et la classer, l’uniformiser (les logs ont pleins de format différents)
- chercher dedans par date efficacement.
- croiser les données
La stack ELK
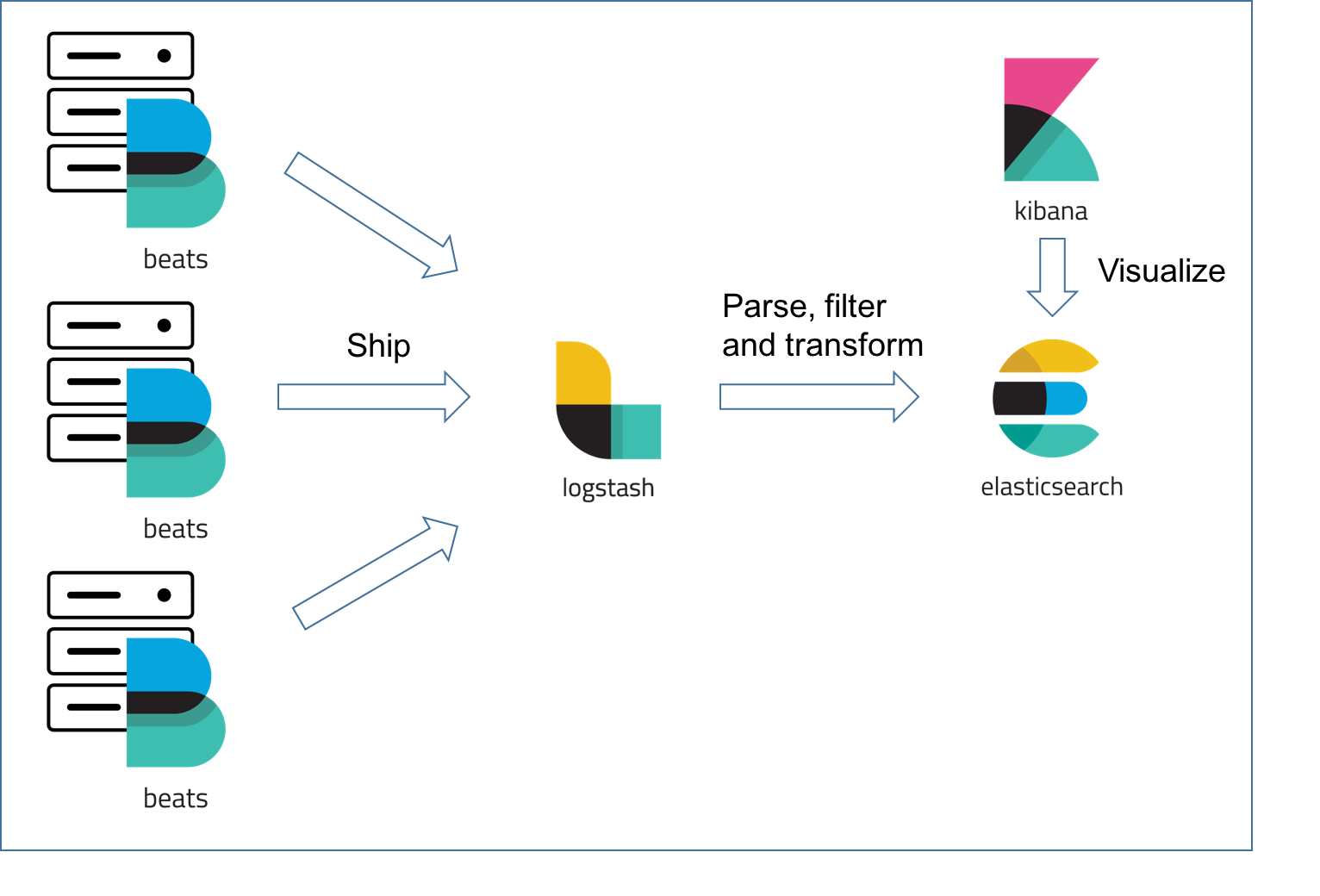
La stack ELK
-
Les Beats pour lire les données depuis plusieurs machines. Les principales sont :
- FileBeat : lire des fichiers de log pour les envoyer à Logstash ou directement à Elasticsearch
- MetricBeat : récupérer des données d’usage, du CPU, de la mémoire, du nombre de process NGINX
-
Logstash : récupère les logs pour les traiter avant de les envoyer dans Elasticsearch
- formater des logs
- transformer les données avant de les mettre dans Elasticsearch
-
Elastic APM
- Elastic APM permet d’envoyer des mesures d’une application à Elasticsearch, il y a un agent à intégrer qui dépend du langage : l’agent d’une applicatin Java par exemple va faire remonter des statistiques sur la JVM.
Quelques forces d’Elasticsearch et ELK
- Facile à agrandir: (elastic) c’est une application automatiquement distribuée.
- Ajout d’un nouveau noeud, réindexation et hop.
- Presque en temps réel : Les évènements sont disponibles pour la recherche presque instantanément
- Recherche très rapide : sur des gros volumes
Exercice I.2)
Calculons la quantité de log que produisent 12 instances d’une application pendant un mois Chaque instance = Un serveur web, une application python + une base de données pour toutes les instances
- Chercher la taille d’une ligne de log ?
- Combien pèse un caractère ?
- Comment mesurer la quantité de lignes produites par une application ?
- on va retenir 200 lignes par minute en moyenne pour le serveur web
- 120 pour l’application python
- 60 pour la DB -> c’est très variable
- Faire le calcul
- Conclusions…