2 - Elasticsearch
Elasticsearch
Elasticsearch est à la fois :
- une base de données distribuée (plusieurs instances de la base de données sont connectées entre elles de manière à assurer de la redondance si un des nœuds en vient à avoir des problèmes)
- un moteur de recherche puissant, basé sur un autre logiciel appelé Apache Lucene
Elle fait partie des bases de données de type NoSQL.
Comparaison entre les BDD SQL et NoSQL.
- SQL : des tableaux qu’on peut croiser = Jointures
ex: MySQL, PostgreSQL, Microsoft Access
- NoSQL: des documents qu’on peut filtrer et aggréger
ex: MongoDB, CouchDB, Elasticsearch
Le point commun des deux : Stocker des données de base pour une application.
Ex: un Site ou web ou un utilisateur a acheté une liste de produit
- utilisateur: login, email, mdp, présentation, age, image de profil
- produit: ref, description, prix, photo
- facture et garantie: documents complexes mais créés une fois pour toute.
SQL: On veut avoir un historique des achats et les documents afférents : on relie formellement utilisateurs et les produits à travers un historique d’achat.
NoSQL: On stocke les factures comme des documents JSON.
Côté SQL:
ça donne trois tables
- schéma de données liées en SQL
- concevoir correctement pour pas être coincé : il faut que les données soient reliées aux bons endroits et efficacement.
- effectuer une recherche de texte approximative (par exemple) ou un peu complexe (comme Google) n’est pas simple.
Côté NoSQL:
des documents JSON qu’on va récupérer avec une référence
- le schéma est facultatif et moins important
- fait pour chercher plutôt que supporter le modèle des données.
- moins de pression à concevoir correctement pour pas être coincé : il faut que les données répondent quand même à un schéma qu’on va essayer de ne pas trop modifier, mais ce n’est pas un problème si cela se fait dans un second temps.
Avec des BDD SQL et NoSQL
- SQL : données homogènes, cohérentes et fortement changeantes
- NoSQL : données complexes mais moins de cohérence
Elasticsearch : une sorte de BDD mais pour la recherche de texte
- Assez proche de MongoDB : on met des documents JSON dedans en HTTP.
- On jette des trucs dedans qu’on voudrait analyser plus tard
- On explore ces éléments en faisant des recherche et des graphiques
A chaque tâche son outil
- Elasticsearch n’est pas conçu pour soutenir l’application pour toutes ses données, seulement pour la partie recherche / analyse.
- Dans notre cas Elasticsearch sert pour travailler sur les logs
Dev tools
- Pour exécuter directement des requêtes REST (on revient sur ce que c’est juste après)
-
Ctrl+Entrée ou “Play” pour lancer la commande selectionnée.
-
C’est cette vue qu’on va principalement utiliser dans les premières parties.
-
Elle montre mieux les dessous de Elasticsearch.
-
Il faut que vous compreniez bien le principe d’une API REST JSON parce que c’est très répandu.
Connaitre la version de Elasticsearch
Dans la vue dev tools tapez:
GET /
réponse:
{
"name": "ZEWiZLN",
"cluster_name": "elk_formation",
"cluster_uuid": "rGzTBgbXRyev62Ku4vTWFw",
"version": {
"number": "7.14.1",
...
},
"tagline": "You Know, for Search"
}
Version de Elasticsearch
- Version 7.14. C’est important car entre chaque version majeure (3, 4, 5, 6, 7) il y a des changements dans les fonctions (L’API)
- La référence c’est la documentation: https://www.elastic.co/guide/en/elasticsearch/reference/7.14/index.html
- Toutes les fonctions de elasticsearch y sont décrites et on peut choisir la version selon celle installée.
Bonus : Principaux changements entre Elasticsearch 7 et 8
Elasticsearch 8 introduit surtout une modification clé :
- Suppression des *mapping types
Les types de mappage ont été retirés, simplifiant la modélisation des données.
Cela permettait de mettre au sein d’un même index plusieurs “types de document”, maintenant on n’utilise plus qu’un seul type de document par index, appelé
_doc(les mappings, automatiques et manuels (aussi appelés mappings explicites) existent toujours).
L’organisation basique de Elasticsearch
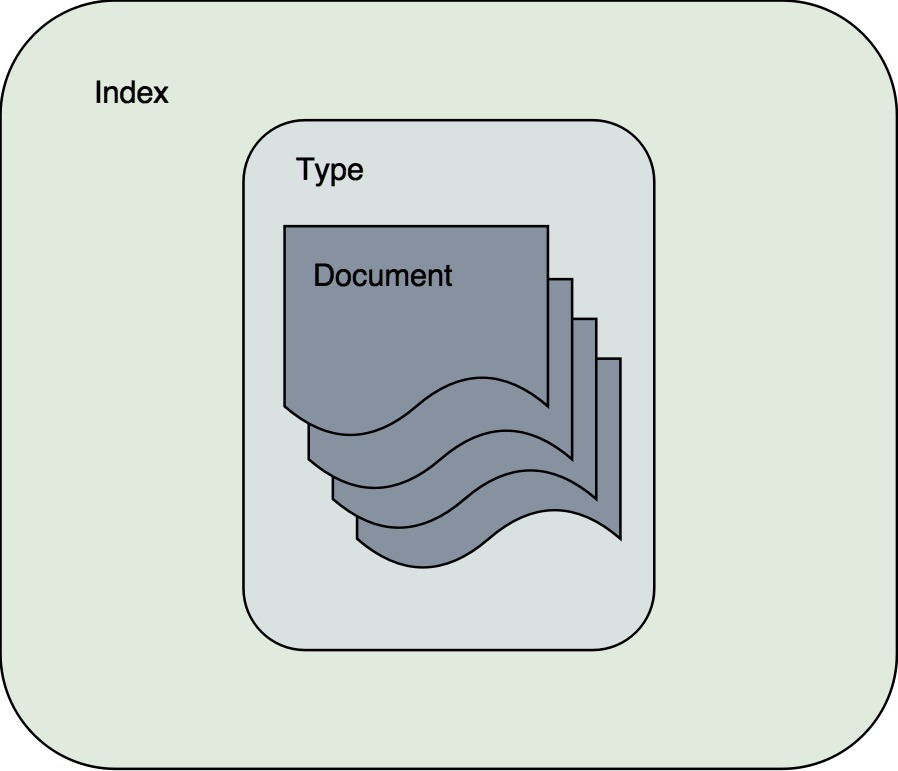
L’architecture basique de Elasticsearch
- Index :
- comme une bibliothèque de documents
- comme une base de données en SQL
- on peut en créer plusieurs (bien sûr)
L’architecture basique de Elasticsearch
- Index avec son Mapping
- un peu comme une table en SQL
- mapping = format c’est
title+author+price+description
mapping signifie représenter/modéliser en anglais.
- Documents
- chaque entrée dans un index avec son id
- ici un livre ou un vol
- un peu comme une ligne dans une table en sql
Les opérations de base de l’API = CRUD
- “ajouter un index/mapping/document” (Create)
- “récupérer/lire un index/mapping/document” (Read)
- “mettre à jour un index/mapping/document” (Update)
- “supprimer un index/mapping/document” (Delete)
Syntaxe d’un appel de fonction
<METHODE> <URI>
<DATA>
PUT /bibliotheque/_doc/1
{
"title": "La Promesse de l'aube",
"description": "[...] J'entendis une fois de plus la formule intolérable [...]",
"author": "Romain Gary"
}
Le BODY
- est facultatif
- est en JSON (JavaScript Objet Notation)
- décrire des données complexes avec du texte
- très répendu
- pas trop dur à lire pour un humain
Syntaxe du JSON
{
"champ1": "valeur1",
"champ2_nombre": 3, // pas de guillemets
"champ3_liste": [
"item1",
"item2",
"item3",
],
"champ4_objet": { // on ouvre un "nouveau json" imbriqué
"souschamp1": "valeur1.1";
...
},
"champ5": "Pour échapper des \"guillemets\" et des \\n" // échappement pour " et \
}
Exercice II.1) syntaxe API et JSON
CRUD et méthode HTTP
<METHODE> <URI>
<DATA>
METHOD en gros (il y a des exceptions sinon c’est pas drôle) :
GET= Read / récupérerPOST= CréerPUT= Mettre à jour / UpdateDELETE= Supprimer
Exercice II.2.1) Gérer les documents dans Elasticsearch.
II.2.2) Gérer les mappings et les index
Mapping implicite et Mapping explicite
Lorsque vous ajoutez un document sans avoir créé de Type de document et de mapping (=format) pour ce type, elasticsearch créé automatiquement un format en devinant le type de chaque champ:
- pour les champs texte il prend le type text + keyword (on verra pourquoi après)
- pour champs numériques il prend le type integer ou float
C’est le mapping implicite Mais si on veux des champs spéciaux ou optimisés il faut créer le mapping soi-même explicitement.
Mapping explicite
Pour avoir plus de contrôle sur les types de champs il vaut mieux décrire manuellement le schéma de données. Au moins les premiers champs qu’on connaît déjà.
(Il peut arriver qu’on ait pas au début d’un projet une idée de toutes les parties importantes. On peut raffiner le mapping au fur et à mesure)
Afficher le(s) mapping(s)
GET /<index>/_mapping
Exemple:
GET /kibana_sample_data_flights/_mapping
Les types de données (datatypes)
Un documents dans elasticsearch est une données complexe qui peut être composé de nombreux éléments hétérogènes
Les types les plus importants: text, keyword, integer, float, date, geo_point
Types texte
- text : Pour stocker du texte de longueur arbitraire. Indexé en recherche fulltext. On y reviendra: ça veut dire que tous les mots du texte sont recherchables.
- keyword : Du texte généralement court pour décrire une caractéristique du document
- Exemple: OriginWeather décrit la météo cloudy
Types nombre
- integer : un nombre entier
- float : nombre à virgule
Il existe d’autres types de nombres plus courts ou plus longs (donc plus gourmand en espace).
Type date
Comme on stocke souvent des évènements dans elasticsearch il y a presque toujours une ou plusieurs date dans un document. En fait ce n’est pas vraiment une date mais ce qu’on appelle un timestamp qui va jusqu’à la milliseconde.
Type geo_point
Pour stocker un point géographique. C’est une paire de nombres : latitude et longitude. On verra ça un peu dans kibana plus tard. La stack Elk fournit plein d’outil pour stocker des données géolocalisés et les visualiser : C’est un besoin courant. Exemple : savoir d’où viennent les requêtes sur votre application pour connaître vos usagers.
Exercice II.2.2)
II.3) API REST et JSON ?
Revenons sur le format de l’API
C’est quoi ce format d’appel de fonction: METHOD URI DATA ?
HTTP
- Le protocole le plus connu pour la communication d’applications
- protocole = requêtes et réponses formalisées entre deux logiciels
- exemples:
- navigateur <-> serveur apache
- kibana <-> elasticsearch
- application web <-> mongoDB
En requête
- url: http://192.168.0.34:4561 ou http://monelastic.net/catalog/product/3/_update
- method: GET, POST, PUT, DELETE, HEAD, … autres moins connues
- data: données du message falcultatif
En réponse
- un fichier avec
- un en tête nommé HEAD qui gère décrit la réponse avec des métadonnées
- le HEAD contient notamment un code de réponse :
- 200 = OK
- 404 = non trouvé
- un contenu nommé BODY
API REST
-
API = Application Programming Interface : “Une liste de fonctions qu’on peut appeler de l'extérieur d’un logiciel”
-
REST signifie REpresentational State Transfer.
-
C’est un format standard (le plus répendu) pour une API.
-
C’est-à-dire une façon de décrire la liste des fonctions et leurs paramètres.
Curl, l’outil HTTP
GET /devient :curl -XGET http://localhost:9200/
PUT /catalog/product/1
{
"sku": "SP000001",
"title": "Elasticsearch for Hadoop",
"description": "Elasticsearch for Hadoop",
"author": "Vishal Shukla",
"ISBN": "1785288997",
"price": 26.99
}
Devient :
$ curl -XPUT http://localhost:9200/catalog/product/1 -d '{ "sku": "SP000001",
"title": "Elasticsearch for Hadoop", "description": "Elasticsearch for
Hadoop", "author": "Vishal Shukla", "ISBN": "1785288997", "price": 26.99}'
Exercice II.3) Utiliser curl
III) Rechercher et analyser dans Elasticsearch
III.1) Index et recherche de texte
Comme dans une bibliothèque
Indexer des documents c’est comme les ranger dans une bibliothèque. Si on range c’est pour retrouver. Mais on veut vouloir trouver de deux types de façon.
- Recherche exacte: On veut pouvoir trouver les documents rangés dans la catégorie litterature anglaise ou bandes déssinées SF.
- Recherche en texte intégral ou fulltext : On veut pouvoir trouver les documents qui ont Lanfeust ou éthique dans leur titre.
Recherche exacte
- Quand je cherche littérature anglaise je ne veux pas trouver les documents de littérature espagnole bien qu’il y ai le mot “littérature” en commun.
- Je veux que les termes correspondent précisément ou dit autrement je veux que littérature anglaise soit comme une seule étiquette, pas un texte.
- C’est le fonctionnement d’une recherche classique dans une base de données SQL:
SELECT * FROM bibliothèque WHERE genre = "littérature anglaise";
Recherche exacte 2
On utilise _search, query et term.
GET /<index>/_search
{
"query": {
"term": {
"<field>": "<value>"
}
}
}
Recherche fulltext
- Retrouver non pas l’ensemble des livres d’un genre mais un livre à partir d’une citation.
- Pour cela on fait un index inversé qui permet une recherche fulltext.
- Elasticsearch est spécialement fait pour ce type de recherche. Il le fait très efficacement et sur des milliards de lignes de texte.
- exemple: github utilise elasticsearch pour indexer des milliers de dépôts de code.
On utilise _search, query et match.
GET /<index>/_search
{
"query": {
"match": {
"<field>": "<value>"
}
}
}
Différence entre les champs keyword et text
-
Un champ keyword n’est pas indexé en mode fulltext : la méthode match ne fonctionne pas en mode partiel
-
Un champ text est automatiquement indexé en mode fulltext: la méthode match fonctionne
-
un champ textuel créé implicitement est double : le champ principal en text + un sous champ keyword:
- exemple: title est un champ text, title.keyword est un champ keyword
Exercice III.1)
III) Life inside a cluster
- shard
- dimensionner un cluster
- haute disponibilité
- endpoint switching
- fallback automatique
Exercice:
- configurer et constater qu’on a le bon nombre de noeuds
- vérifier que quand il y en a un qui tombe ça marche toujours
III.2) Recherche avec requête multiple et filtre
Des requêtes complexes pour l’analyse
Elasticsearch est puissant pour l’analyse car il permet de combiner un grande quantité de critères de recherche différent en même temps et de transformer les données récupérer pour les rendre significatives.
Imaginons qu’on veuille chercher tous les avions qui ont décollé de New York sous la pluie depuis un mois et qui ont un prix moyen supérieur à 800$. Par exemple pour créer une mesure du risque économique que le dérèglement climatique fait peser sur une companie ?
On va devoir écrire une requête complexe.
Plusieurs outils
- des requêtes composées tous les vols qui vérifie condition A ET condition B ET PAS condition C
- des filtres de requêtes garder que les vols dont le prix est entre 300 et 1000 €
- des aggrégations de requêtes (somme, aggrégation géographique) chercher en gros le chiffre d’affaire d’une companie : faire la somme des trafifs de ses vols.
Repasser à Kibana
On pourrait tout faire avec l’API mais ce serait pas très fun et on s’arracherait vite les cheveux.